INDEX
인라인 함수
인라인 함수
-
복붙과 비슷
-
코드의 가독성과 성능을 둘 다 잡은 토끼
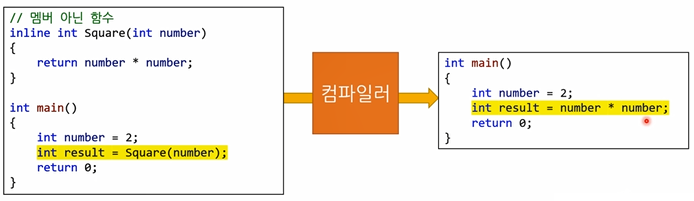
인라인 미사용
Cat* myCat = new Cat(2, "Coco"); int age = myCat->GetAge();인라인 사용
Cat* myCat = new Cat(2, "Coco"); int age = myCat->mAge; -
매크로와 매우 비슷한 개념
매크로 예시
#define SQUARE(x) (x)*(x) SQUARE(3); // = (3)*(3)- 단 매크로는 컴파일러가 아닌 전처리기가 해줌
- 매크로는 디버깅이 힘들다
- 콜스택에 함수이름이 안보임
- 중단점 설정도 불가능
- 매크로는 범위(scope)를 준수하지 않음
- 정말정말 매크로르 쓸 이유가 있지 않는 한 인라인 함수를 쓰자!
함수 호출할 때
-
함수는 메모리 안에 “할당”되어있음
-
함수를 호출하기 위해 필요한 단계들
- 변수들을 스택에 푸쉬(push)
- 함수 주소로 점프
- 함수를 실행
- 호출자 함수로 다시 점프
- 1번 단계에서 넣어뒀던 변수들을 팝(pop)
- 호출 단계가 좀 많다
- 그래서 좀 느림
- CPU 캐시에 최적이 아닐 수도 있다
- 모던 cPU 아키텍쳐에서는 더 느림
- 그런데 아직도 “모든걸 함수로 만들라!” 라는 잘못된 조안이 떠돌아다닌다.
인라인 함수의 동작 원리
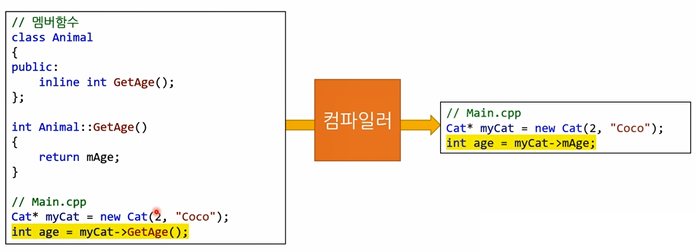
인라인 함수를 쓸 때 주의점
- inline키워드는 힌트일 뿐
- 따라서 인라인 안될 수도 있음..
- 컴파일러가 자기 맘대로 아무 함수나 인라인 할 수도 있음
- 인라인 함수 구현이 헤더 파일에 위치해야 함
- 복붙을 하려면 컴파일러가 그 구현체를 볼 수 있어야 하기 때문에
- 각 cpp파일은 따로 컴파일됨
- 따라서 b.h를 인클루드하는 a.cpp파일을 컴파일할때 컴파일러는 b.cpp에 뭐가 들어있는지 모름
- 간단한 함수에 해야함
- 특히 getter나 setter에
- 실행파일의 크기가 증가하기 쉬움
- 동일 코드를 여러번 복붙하니까
- 남용하지 말것
- 실행파일이 작을수록 CPU캐시하고 잘 작동 -> 속도가 빨라질 수 있음
인라인 함수 사용법
멤버 아닌 인라인 함수 사용법
inline <return-type> <function-name> (<argument-list>) { //... };
인라인 멤버 함수
inline <return-type> <class-name>::<function-name> (<argument-list>) { //... };
static 키워드
static 키워드
- 범위(scope)의 제한을 받는 전역 변수
- 어떤 범위인가?
- 파일 속
- 네임스페이스 속
- 클래스 속
- 함수 속
extern 키워드
- 다른 파일의 전역변수에 접근을 가능케 해줌
함수 속 정적 변수
예시
void Acc(int number) { //초기화는 한번만 됨 static int result = 0; result += number; std::cout<<"result = "<<result<<std::endl; } int main() { Acc(10); // 10 Acc(20); // 30 return 0; }
정적 멤버 변수
-
*클래스당 하나의 COPY만 존재
-
캐채의 메모리 레이아웃의 일부가 아님
-
클래스 메모리 레이아웃에 포함
-
exe파일 안에 필요한 메모리가 잡혀있음
- 컴파일러가 이 변수의 인스턴스가 몇 개 존재해야 하는지 알기에
- 오직 하나!!
-
예시
>```cpp >// Cat.h >class Cat >{ > public: > Cat(); > private: > static int mCount; >}; > >// Cat.cpp >int Cat::mCount = 0; >Cat::cat() >{ > mCount++; >} >```
정적 멤버 변수 베스트 프랙티스
- 함수 안에서 정적 변수를 넣지 말것
- 클래스 안에 넣을 것
- 전역변수 대신 정적 멤버변수를 쓸 것
- 범위(scope)를 제한하기 위해
정적 멤버 함수
-
논리적인 범위(scope)에 재한된 전역 함수
-
해당 클래스의 정적 멤버에만 접근 가능
-
개체가 없이도 정적 함수를 호출할 수 있음
-
예시
//Math.h class Math { public: static int Square(int number); } //Math.cpp int Math::Square(int number) { return number* number; }//main int main() { Math::Square(10); }
예외
C++에서의 예외
-
예외에 대해서는 이미 다른 코스에서 배웠음
-
C++도 예외를 “지원”
-
- 지원을 하지만 생각보다 부족하고 무시받고 있다
-
허나, C++에서는 예외의 중요성이 조금 떨어짐
-
언어를 불문하고 심하게 남용되고 있음
- 따라서 올바른 사용법을 중점적으로 살펴보자
Java는 어딜 봐도 예외 투성이
- 많아도 너무 많다
- if문으로 해결할 수 있어도 예외처리를 한다..
- 예외로부터 안전한 코드를 작성하기 힘듦
- 사람의 사고방식은 선형적
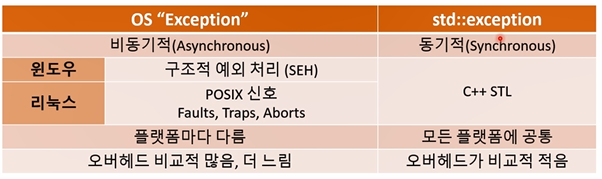
C++의 예외는 어디서 올까?
- 프로그래머가 만든 것
- C++ 표준 라이브러리가 많은 예외를 던지기도 함
- 하지만 Java나 C#에서 당연히 있는 예외가 C++에서는 없음
- 컨트롤 할 수 있는 예외를 exception으로 처리 할 경우 낭비다!
예외 - 범위 이탈, 0으로 나누기
범위 이탈 예외
#include<exception> int main() { std::string myCatName = "Coco"; try { char ch = myCatName.at(5); } catch(const std::out_of_range& e) { std::ceer<<"out of range: "<<e.what()<<std::end; } catch(const std::exception& e) { std::cerr<<"exception:" <<e.what()<<std::endl; } return 0; }
try/catch가 없을 경우

범위 이탈 예외 해결책
std::string myCatName = "Coco"; const size_t INDEX = 5; if(INDEX < myCatName.size()) { char ch = myCatName.at(INDEX); //....이하 코드 생략.... }컨트롤 할 수 있다! -> try/catch를 쓰는 건 낭비
0으로 나누기
-
C++의 예외가 아니라 운영체제의 예외란다.
- 인터럽트 발생
해결책
if(b != 0) { return a/b; }이것도 컨트롤 할 수 있다!
NULL개체 참조
- 이것도 C++의 예외가 아니다!
- 이것도 if문으로 처리 가능…
예외 생성자
예외 생성자
대부분의 예외는 불필요
-
이론적으로 말하면 생성자의 경우에는 유용함
-
생성자 예외 발생 예시
Inventory::Inventory(int count) { mSlots = new int[count]; }mSlots가 NULL일 경우? -> 반환할 값도 없고 하니, 예외가 필요하다.
생성자 예외 던지기
//Exception.h #include<exception> struct SlotNullEsception : public std::sxception { const char* what() const throw() { return "Slot is NULL"; } };//Inventory.cpp Inventory::Inventory(int slotCount) { mSlots = new int[slotCount]; if (mSlots == NULL) { throw slotNullException(); } }//Main.cpp Inventory* myInventory = nullptr; try { myInventory = new Inventory(5); } catch(const SlotNullException& e) { std::cerr << e.what() << std::endl; } catch(const std::exception& e) { //다른 에러들 }
그럼 생성자에서 쓰는 예외는 괜찮을까?
-
Yes
-
메모리 부족 때문에 예외가 발생하면?
- 프로그램 종료? -> 크래시랑 다른게 없다
- 생성자 호출 재시도? -> 하지만 이미 메모리가 없다..
예외 - C의 에러코드
C·++ vs 다른 언어들
- C++의 예외처리를 사용하는 회사에서 근무할지도 모름
- 그래도 C++도 예외처리를 지원할 수 있다는 정도만 기억하자
- 다른 언어들은 지금까지 예외를 광범위하게 사용해 왔음
- 하지만 변화가 일어나고 있음
예외 에러 코드보다 예외가 더 낫다
진실
- 에러코드는 예외 처리 못지 않게 가독성이 높음
- 혹은 더 높을 수도 있다
- 대부분의 프로그래머들은 예외를 제대로 처리하지 못함
적절한 예외처리
적절한 예외 처리 전략
-
유효성 검사/예외는 오직 경계에서만
-
- 밖에서 오는 데이터를 제어할 수 없기 때문
- 예) 외부에서 들어오는 웹 요청, 파일 읽기/쓰기, 외부 라이브러리
-
일단 시스템에 들어온 데이터는 다 올바르다고 간주할 것
-
- assert를 사용해서 개발 중 문제를 잡아내고 고칠 것
-
예외 상황이 발생할 때는 NULL을 능동적으로 사용할 것
-
- 하지만 기본적으로 함수가 NULL을 반환하거나 받는 일은 없어야 함
- 코딩 표준 : 만약 NULL을 반환하거나 받는다면 함수의 이름을 잘 지을것
경계에서의 예외처리
//C# 방식 string ReadFileorNULL(string filename) { if(!File.Exists(filename)) { return null; } try { return File.LoadAllText(filename); } catch(Exception e) { return null; } }
일단 시스템에 들어온 데이터는 다 올바르다고 간주
-
assert를 사용하여 개발 중 문제를 잡아내고 고칠 것
` int convertToHumanAge(const Animal* pet) { Assert(pet != NULL); //… } `
코딩 표준
- 매개변수가 NULL이 될 수 있으면 매개변수 이름 뒤에 ‘OrNull’을 붙인다
const char* GetCoolName(const char* startWithOrNull) const;
const char* GetHobbyOrNull() const;
예외는 만병통치약이 아니다
-
동일한 프로그래머가 로직과 예외를 모두 작성
-
- 로직이 잘못돼 있으면 예외도 틀렸을 가능성이 높음
- 동일한 프로그래머가 작성한 유닛 테스트가 한계를 갖는 이유
- 양질의 소프트웨어는 예외가 아니라 철저한 테스트 계획에서 만들어진다
개발 중 버그 잡기
-
이걸 라이브 서버에서는 해선 안됨
-
- 하지만 예외 때문에 그런 유혹을 받음
-
개발 중 코드에서 버그를 잡기 위해서는 assert를 사용
-
- 전제 조건, 사후 조건, 그리고 불변값 확인
- 또한 assert가 실패하면 올바른 호출 스택을 볼 수 있음
-
품질관리(QA)가 제대로 이루어지지 않았다면 차라리 소프트웨어가 뻗어 버리게 만드는 게 좋다
-
- 문제가 바로 드러나기에 바로 고칠 수 있기 때문
- 하지만, 안전과 생명에 관련되는 소프트웨어라면 예외
시체보다는 좀비가 낫지 않나요?
-
예외가 없는 경우 예외가 있는 경우 프로그램에서 크래시 발생
크래시에서 메모리 덤프를 얻을 수 있음
개발자는 덤프 파일을 열어 디버깅 할 수 있음왼쪽에서 언급한 어떠한 것도 안 할 가능성이 높음
아마 어딘가에서printf로 찍은 로그나 보며 디버깅 할듯