INDEX
STL
STL
-
표준 템플릿 라이브러리 컨테이너
-
목록
벡터
맵
셋
스택
큐
리스트
디큐
….
-
목적
템플릿 기반
모든 컨테이너에 적용되는 표준 인터페이스
메모리 자동 관리
반복자
- STL컨테이너를 순회할 때는 반복자(iterator)를 쓰는게 표준 방식
반복자(iterator)
반복자
- 컨테이너의 요소들을 순회하는 데 사용됨
- 사실상 포인터
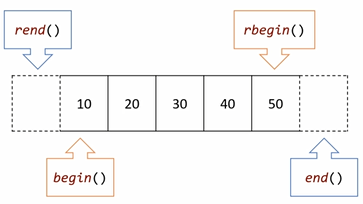
begin()- 컨테이너의 첫 번째 요소를 가리키는 반복자를 반환
end()- 컨테이너의 마지막 요소 바로 뒤의 요소를 가리키는 반복자를 반환
const_iterator
-
매개변수가 바뀌지 않는 순환자
-
예시
vector<int>::const_iterator iter = scores.begin();
역방향 반복자
-
end()에서 시작하여 begin()까지 반복하고 싶을 때 사용
-
rbegin(),rend(): -
예시
vector::reverse_iterator iter = scores.rbegin();
그림예시
벡터
벡터
- 어떤 자료형도 넣을 수 있는 동적 배열
- 기본 데이터
- 클래스
- 포인터
- 그 안에 저장된 모든 요소들이 연속된 메모리 공간에 위치
- 요소 수가 증가함에 따라 자동으로 메모리를 관리해 줌
- 어떤 요소에도 임의로 접근 가능
x라는 vector와 같은 크기 및 데이터를 갖는 vector 생성법(복사생성자)
std::vector<<type>><name>(const vector& x);
std::vector<int> scores1(scores); //scores의 사본
벡터의 크기 변경하기
-
새 크기가 vector의 기존 크기보다 작으면 초과분이 제거됨
-
새 크기가 vector의 용량보다 크면 재할당이 일어남
-
resize(size_t n);std::vecotr<int> scores; scores.reserve(3); scores.push_back(30); //30 scores.push_back(100); //30, 100 scores.push_back(70); //30, 100, 70 scores.resize(2); //30, 100 for(auto k : scores) { std::cout<< k <<" "; //"30 100" }
특정 위치에 요소 삽입하기
-
데이터 복사 (느림)
-
재할당 할 수도 있음
-
insert(iterator, value);std::vecotr<int> scores; scores.reserve(4); scores.push_back(10); //10 scores.push_back(50); //10, 50 scores.push_back(38); //10, 50, 38 scores.push_back(100); //10, 50, 38, 100 std::vector<int>::iterator it = scores.begin(); it = scores.insert(it, 80); //80, 10, 50, 38, 100
특정 위치에 요소 삽제하기
-
데이터 복사 (느림)
-
erase(it);std::vecotr<int> scores; scores.reserve(4); scores.push_back(10); //10 scores.push_back(50); //10, 50 scores.push_back(38); //10, 50, 38 scores.push_back(100); //10, 50, 38, 100 std::vector<int>::iterator it; it = scores.begin(); it = scores.erase(it); //50, 38, 100
요소 대입하기
-
assign(size_t n, <data>);-
n개의 <data>값을 벡터에 넣는다
vector<int> anotherScores; anotherScores.assign(7, 100); //100, 100, 100, 100, 100, 100, 100
-
두 벡터 교환하기
-
swap(vector& other); -
같은 자료형의 두 벡터를 맞바꾼다
vector<int> scores; //10, 20, 30 vector<int> anotherScores; //40 ,50, 60 socres.swap(anotherScores); //scores : 40, 50, 60 //anotherScores : 10, 20, 30
벡터의 모든 요소 제거하기
clear();- vector의 크기는 0이 되고 용량은 변하지 않음
개체를 직접 보관하는 벡터의 문제점
-
개체가 크면 메모리 재할당이 일어날 가능성이 높아진다!
-
그래서 대신 포인터를 저장하면 된다!
-
단, 모든 요소에 delete를 꼭 호출할 것
- 또한 지운 후 이 포인터들을 계속 사용하면 안됨!!
예시
int main() { vector<Score*> scores; scores.push_back(new Score(30, "C++")); scores.push_back(new Score(87, "Java")); for(vector<Score*>::iterator iter = scores.begin(); iter != scores.end(); ++iter) { delete *iter; } scores.clear(); }
-
벡터의 장점
- 순서에 상관없이 요소에 임의적으로 접근 가능
- 제일 마지막 위치에 요소를 빠르게 삽입 및 삭제
벡터의 단점
- 중간 요소 삽입 및 삭제는 느림
- 재할당 및 요소 복사에 드는 비용
맵
맵
- key와 value가 동시에 저장되는 컨테이너
- 키는 중복될 수 없음
- C++맵은 자동 정렬되는 컨테이너다..
- 이진 탐색 트릭 기반
- 오름차순
맵 만들기
map<<key_type>,<value_type>><name>:빈 맵 생성map<<key_type>,<value_type>><name>(const map& x): x라는 map과 같은 크기(size)와 데이터를 갖는 map을 생성
std::map<std::string, int> simpleScoreMap; std::map<StudentInfo, int> simpleScoreMap; std::map<std::string, int> copiedSimpleScoreMap(copiedSimpleScoreMap);
맵 사용 예시
#include<map> int main() { std::map<std::string, int> simpleScoreMap; simpleScoreMap.insert(std::pair<std::string, int>("Mocha",100)); simpleScoreMap.insert(std::pair<std::string, int>("Coco", 50)); simpleScoreMap["Mocha"] = 0; std::cout<<"Current size: " << simpleScoreMap.size() << std::endl; return 0; }
페어(pair), 쌍
pair<first_type, second_type>- 두 데이터를 한 단위로 저장하는 구조
insert
-
새 요소를 map에 삽입한다
-
반복자와 bool값을 쌍으로 반환
- 반복자는 요소를 가리키고
- bool값은 삽읍 결과를 알려줌
-
키를 중복으로 삽입할 수 없음
//<iterator, true>를 반환한다 simpleScoreMap.insert(std::pair<std::string, int>("Mocha", 100)); //<iterator, false>를 반환한다 simpleScoreMap.insert(std::pair<std::string, int>("Mocha",0));
operator[]
-
mapped_type& operator[](const key& key); -
key에 대응하는 값을 참조로 반환한다
-
map에 키가 없으면 새 요소를 삽입한다
-
map에 키가 있으면 그 값을 덮어씀 (주의 필요!!)
std::map<std::string, int>simpleScoreMap; simpleScoreMap["Coco"] = 10; //새 요소를 삽입 simpleScoreMap["Coco"] = 50; //"Coco"의 값을 덮어쓴다
자동 정렬
- key값에 따라 오름차순으로 정렬됨
요소 찾기
-
operator[]를 사용할 시 문제 생길 수 있음 -
find()- map안에서 찾으면 그에 대응하는 값을 참조로 반환
- 찾지 못하면
end()반환
-
예시
std::map<std::string,int>::iterator it = simpleScoreMap.find("Mocha"); if(it != simpleScoreMap.end()) { it->second = 80; }
swap(), clear(), erase()
-
swap()- 두 map의 키와 값을 바꾼다
-
clear()- 맵을 비운다
-
erase()-
map의 요소들을 제거한다
std::map<std::string,int>::iterator foundIt = simpleScoreMap.find("Mocha"); simpleScoreMap.erase(foundIt); simpleScoreMap.erase("Coco");
-
개체를 키로 사용하기
-
개체를 키로 정렬하려면
operator<()를 정의해야함- 정렬이 되야 하기 때문
예시
bool StudentInfo::operator<(const StudentInfo& other) const { if (mName == other.mName) { return mStudentID < other.StudentID; } return mName < other.mName; } -
다른 방법 : map을 만들 때 비교함수(compare)를 넣을 수도 있음
-
남이 만든 구조체를 바꾸고 싶을 때 사용
예시
struct StudentInfoComparer { bool operator()(const StudentInfo& left, const StudentInfo& right) const { return (left.getName() < right.getName()); } } std::map<StudentInfo, int, StudentInfoComaprer> scores;
-
map의 장단점
- 장점
- list나 vector보다 탐색 속도가 빠름
- O(logN)
- list나 vector보다 탐색 속도가 빠름
- 단점
- 자동으로 정렬됨
- 해쉬맵이 아님, 따라서 O(1)이 아님
- C++에 해결책이 있음
셋
셋
-
정렬되는 컨테이너
-
중복되지 않는 키를 요소로 저장함
-
이진 탐색 트리 기반
-
- 오름 차순
- 맵에서 value를 없앤거…
장점과 단점
- map과 같음
큐
- 선입 선출 자료구조
스택
- 후입 선출 자료구조
리스트
리스트
- 실무에서는 거의 벡터와 맵으로 끝나긴 함…
- C++에서 STL리스트란?
- 양방향 연결 리스트(이중 연결 리스트)
operator[]가 없음- 양쪽 긑에서 삽입/제거 가능
요소 삽입 삭제
push_front(),push_back()pop_front(),pop_back()erase()
리스트의 다른 메서드들
- 정렬하기
- 두 리스트 합치기
- 한 리스트에서 빼 내어 다른 리스트에 넣기
- 중복인 요소들 제거하기
- …
장점과 단점
- 장점
- 삽입과 제거에 걸리는 시간 : O(1)
- 어느 위치든 삽입/삭제 가능
- 단점
- 탐색이 느린 편
- 임의적으로 접근 불가
- 메모리가 불연속적
- cpu 캐쉬와 잘 작동하지 않음
기타
멀티셋
- 중복 키를 허용
- 요소를 수정하면 안 됨
멀티맵
- 중복 키를 허용
덱(디큐)
- Double-ended queue의 약자
-
양쪽 끝에서 요소 삽입과 삭제 가능
-
우선순위 큐
- 자동 정렬되는 큐