[pandas] Grouping
Grouping
주어진
DataFrame에 대하여 한개 이상의column을 기준으로DataFrame자체 또는column을 grouping 또는 분류할 수 있다.groupby라는 keyword를 사용한다.
다음의 예제를 고려하자.
import numpy as np
import pandas as pd
my_dict = {'학과' : ['컴퓨터', '체육교육과', '컴퓨터', '체육교육과', '컴퓨터'],
'학년' : [1, 2, 3, 2, 3],
'이름' : ['홍길동', '김연아', '최길동', '아이유', '신사임당'],
'학점' : [1.5, 4.4, 3.7, 4.5, 3.8]}
df = pd.DataFrame(my_dict)
display(df)
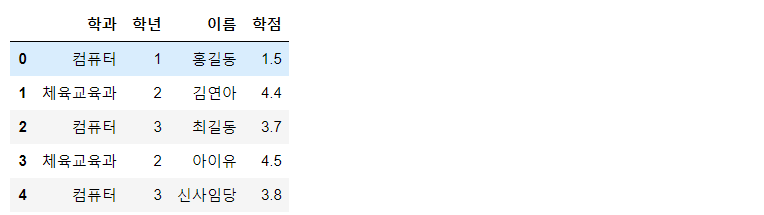
Series의 Grouping
DataFrame의 하나의column을 grouping 하는 개념이다.
groupby: grouping을 위한 keyword
dept = df['학점'].groupby('학과') # 학과를 기준으로 학점을 grouping한다.
print(dept) # <pandas.core.groupby.generic.SeriesGroupBy object at 0x000001415A6EF7C8>
## 학과를 기준으로 학점을 분류를 해놨기 때문에 값이 나오지 않는다.
get_group: grouping 된것중에 원하는 group을 가져올 수 있다.
print(dept.get_group['컴퓨터'])
## 0 1.5
## 2 3.7
## 4 3.8
## Name: 학점, dtype: float64
## Series를 grouping했으므로 Series로 출력된다.
size,mean: 모든 group들의 개수와 평균값을 한번에 확인 가능하다.
print(dept.size())
## 학과
## 체육교육과 2
## 컴퓨터 3
## Name: 학점, dtype: int64
print(dept.mean())
## 학과
## 체육교육과 4.45
## 컴퓨터 3.00
## Name: 학점, dtype: float64
Series의 2단계 Grouping
기준
column이 하나가 아닌 경우를 사용할 수 있다. 기준 2개를 사용를 한 경우를 알아본다.
groupby: 기준이 되는column들을list형태로 넣어준다.
dept_rate = df['학점'].groupby([df['학과'],df['학년']])
print(dept_rate.size())
## 학과 학년
## 체육교육과 2 2
## 컴퓨터 1 1
## 3 2
## Name: 학점, dtype: int64
print(dept_rate.mean())
## 학과 학년
## 체육교육과 2 4.45
## 컴퓨터 1 1.50
## 3 3.75
## Name: 학점, dtype: float64
## Series와 DataFrame의 index와 column에 multi index를 지원해주는것을 알 수 있다.
unstack: 최하위 index를 column으로 설정해DataFrame으로 만들어 준다.
dept_rate = df['학점'].groupby([df['학과'],df['학년']]) # 최하위 column : '학년'
display(dept_rate.size().unstack())

display(dept_rate.mean().unstack())

DataFrame의 Grouping
Series뿐만 아니라DataFrame또한 grouping 가능하다.
groupby:Series에 사용할 때와 달리DataFrame변수명을 포함해 입력할 필요없다.
df_group_dept = df.groupby(df['학과'])
print(df_group_dept) # <pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001415A6EF488>
## Series와 달리 DataFrame으로 찍힌다.
display(df_group_dept.get_group('컴퓨터')) # DataFrame

display(df_group_dept.mean())

DataFrame의 2단계 Grouping
기준
column이 하나가 아닌 경우를 사용할 수 있다. 기준 2개를 사용를 한 경우를 알아본다.
groupby:Series와 마찬가지로 기준이 되는column들을list형태로 넣어준다.
df_dept_year = df.groupby(['학과','학년'])
display(df_dept_year.mean()) # multi index를 사용한다.

unstack:최하위 index를DataFrame의 column으로 설정한다.
display(df_dept_year.mean().unstack())

Grouping의 반복 처리
grouping 된 것들을
for문을 사용해 처리할 수 있다. grouping 처리된 것들은tuple형태로 (기준, Series(or DataFrame)) 으로 구성되어 있다.

for (dept, group) in df.groupby(['학과']):
print(dept)
display(group)

for ((dept,year), group) in df.groupby(['학과','학년']):
print(dept)
print(year)
display(group)
