[DL] ImageDataGenerator의 사용 - 2
ImageDataGenerator2의 사용(개와 고양이)
TF2.X 에서 이미지 증식을 위해서 사용하는 ImageDataGenerator를 사용해 CNN 학습을 해본다.
사용 Library
사용하는 library들이다.
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D, Dropout
from tensorflow.keras.optimizers import Adam
데이터셋
train data와 validation date를 정의한다.
train_dir = './data/cat_dog_full/train'
validation_dir = './data/cat_dog_full/validation'
## 전체 데이터가 25,000장 (고양이 : 12,500, 개 : 12,500)
## 댕댕이 이미지 train : 7,000장
## 댕댕이 이미지 validation : 3,000장
## 댕댕이 이미지 test : 2,500장
ImageDataGenerator
ImageDataGenerator에 대해서 간단히 알아본다.
train_datagen = ImageDataGenerator(rescale=1/255) # pixel의 범위가 0~255이기 때문에 Min-Max 작업과 동일하다. # datagen으로 변수 약어로 사용한다.
validation_datgen = ImageDataGenerator(resize=1/255)
ImageDataGeneratorinput 값에 대해서 알아본다.
-
rotation_range: 무작위 회전 각도 범위이다. 정수값을 입력한다. horizontal_flip: 가로로 뒤집는다. boolean 값을 입력한다.-
vertical_flip: 세로로 뒤집는다. boolean 값을 입력한다. rescale: 데이터에 주어진 값을 곱한다.preprocessing_function: 각 input에 적용되는 함수이다. 이미지가 크기 재조절 되고 증강된 후에 함수가 작동한다.
## flow_from_directory 사용
train_generator = train_datagen.flow_from_directory(train_dir,
classes=['cats', 'dogs'],
target_size = (150, 150),
batch_size = 20,
class_mode = 'binary'
)
## validation도 비슷하게 입력한다.
validation_generator = validation_datagen.flow_from_directory(validataion_dir,
classes=['cats', 'dogs'],
target_size = (150, 150),
batch_size = 20,
class_mode = 'binary')
train_dir: train directory 경로classes:list형식으로 class 이름을 차례대로 입력한다. (0, 1 순서로 생각)target_size: 이미지 size를 scaling 한다. (위에서는 150x150으로 변경)batch_size: 배치 사이즈를 의미하는데 밑에model.fit부분에서steps_per_epoch과 관련이 있다.class_mode: 이진분류인 경우'binary', 다중분류인 경우'categorical'(이것이 기본값)
model 구성
Convolution layer, Pooling layer, Fc layer 등을 모델링 한다.
- Convolution layer 및 Pooling layer
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3, 3),
activation='relu',
input_shape=(150,150,3)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2d(filters=64,
kernel_size= (3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3, 3),
activation='rulu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
- FC layer
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(units=512, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['Accuracy'])
history = model.fit(train_generator,
steps_for_epoch = 700, # step_for_epoch : steps_for_epoch × batch_size = 데이터 개수가 되도록하는것이
#모든 data에 대해서 학습한다.
epochs= 300,
validataion_data = validation_generator,
validataion_steps = 300) # 마찬가지로 validation_steps x batch_size 가 되는것이 좋다.
model.save('./cat_dog_full_cnn_model.h5')
결과
Once deleted, variables cannot be recovered. Proceed (y/[n])? y
Found 14000 images belonging to 2 classes.
Found 6000 images belonging to 2 classes.
Epoch 1/30
700/700 [==============================] - 87s 124ms/step - loss: 0.6375 - accuracy: 0.6166 - val_loss: 0.5503 - val_accuracy: 0.7165
Epoch 2/30
700/700 [==============================] - 79s 113ms/step - loss: 0.5225 - accuracy: 0.7420 - val_loss: 0.4893 - val_accuracy: 0.7615
Epoch 3/30
700/700 [==============================] - 78s 111ms/step - loss: 0.4623 - accuracy: 0.7813 - val_loss: 0.4399 - val_accuracy: 0.7973
Epoch 4/30
700/700 [==============================] - 83s 119ms/step - loss: 0.4212 - accuracy: 0.8042 - val_loss: 0.4126 - val_accuracy: 0.8118
Epoch 5/30
700/700 [==============================] - 84s 120ms/step - loss: 0.3876 - accuracy: 0.8244 - val_loss: 0.4080 - val_accuracy: 0.8143
Epoch 6/30
700/700 [==============================] - 83s 119ms/step - loss: 0.3651 - accuracy: 0.8372 - val_loss: 0.4012 - val_accuracy: 0.8183
Epoch 7/30
700/700 [==============================] - 82s 118ms/step - loss: 0.3366 - accuracy: 0.8529 - val_loss: 0.3739 - val_accuracy: 0.8342
Epoch 8/30
700/700 [==============================] - 84s 120ms/step - loss: 0.3115 - accuracy: 0.8664 - val_loss: 0.3456 - val_accuracy: 0.8502
Epoch 9/30
700/700 [==============================] - 85s 121ms/step - loss: 0.2932 - accuracy: 0.8717 - val_loss: 0.3450 - val_accuracy: 0.8493
Epoch 10/30
700/700 [==============================] - 86s 124ms/step - loss: 0.2691 - accuracy: 0.8863 - val_loss: 0.4040 - val_accuracy: 0.8215
Epoch 11/30
700/700 [==============================] - 86s 123ms/step - loss: 0.2509 - accuracy: 0.8946 - val_loss: 0.3297 - val_accuracy: 0.8582
Epoch 12/30
700/700 [==============================] - 85s 122ms/step - loss: 0.2375 - accuracy: 0.9029 - val_loss: 0.3162 - val_accuracy: 0.8675
Epoch 13/30
700/700 [==============================] - 85s 121ms/step - loss: 0.2144 - accuracy: 0.9124 - val_loss: 0.3298 - val_accuracy: 0.8632
Epoch 14/30
700/700 [==============================] - 85s 121ms/step - loss: 0.1946 - accuracy: 0.9189 - val_loss: 0.3064 - val_accuracy: 0.8747
Epoch 15/30
700/700 [==============================] - 84s 120ms/step - loss: 0.1866 - accuracy: 0.9239 - val_loss: 0.3175 - val_accuracy: 0.8727
Epoch 16/30
700/700 [==============================] - 85s 121ms/step - loss: 0.1723 - accuracy: 0.9294 - val_loss: 0.3126 - val_accuracy: 0.8732
Epoch 17/30
700/700 [==============================] - 84s 119ms/step - loss: 0.1527 - accuracy: 0.9376 - val_loss: 0.3766 - val_accuracy: 0.8618
Epoch 18/30
700/700 [==============================] - 83s 119ms/step - loss: 0.1471 - accuracy: 0.9404 - val_loss: 0.3284 - val_accuracy: 0.8725
Epoch 19/30
700/700 [==============================] - 84s 119ms/step - loss: 0.1306 - accuracy: 0.9483 - val_loss: 0.3221 - val_accuracy: 0.8762
Epoch 20/30
700/700 [==============================] - 82s 118ms/step - loss: 0.1179 - accuracy: 0.9559 - val_loss: 0.3445 - val_accuracy: 0.8672
Epoch 21/30
700/700 [==============================] - 82s 117ms/step - loss: 0.1124 - accuracy: 0.9570 - val_loss: 0.3217 - val_accuracy: 0.8783
Epoch 22/30
700/700 [==============================] - 82s 117ms/step - loss: 0.1056 - accuracy: 0.9601 - val_loss: 0.3664 - val_accuracy: 0.8682
Epoch 23/30
700/700 [==============================] - 83s 118ms/step - loss: 0.0920 - accuracy: 0.9636 - val_loss: 0.3717 - val_accuracy: 0.8752
Epoch 24/30
700/700 [==============================] - 84s 120ms/step - loss: 0.0927 - accuracy: 0.9646 - val_loss: 0.3188 - val_accuracy: 0.8815
Epoch 25/30
700/700 [==============================] - 84s 121ms/step - loss: 0.0832 - accuracy: 0.9666 - val_loss: 0.3102 - val_accuracy: 0.8872
Epoch 26/30
700/700 [==============================] - 85s 121ms/step - loss: 0.0746 - accuracy: 0.9730 - val_loss: 0.4070 - val_accuracy: 0.8743
Epoch 27/30
700/700 [==============================] - 84s 121ms/step - loss: 0.0740 - accuracy: 0.9704 - val_loss: 0.3572 - val_accuracy: 0.8835
Epoch 28/30
700/700 [==============================] - 84s 120ms/step - loss: 0.0695 - accuracy: 0.9736 - val_loss: 0.3398 - val_accuracy: 0.8853
Epoch 29/30
700/700 [==============================] - 83s 119ms/step - loss: 0.0617 - accuracy: 0.9772 - val_loss: 0.3619 - val_accuracy: 0.8842
Epoch 30/30
700/700 [==============================] - 83s 119ms/step - loss: 0.0602 - accuracy: 0.9783 - val_loss: 0.3708 - val_accuracy: 0.8857
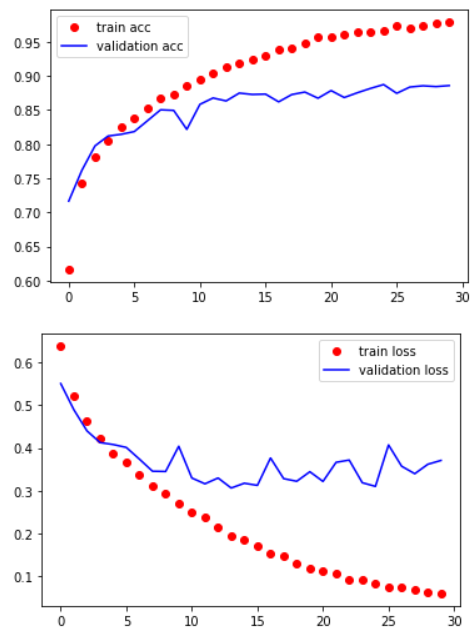
그래프로 살펴보기
%matplotlib inline
import matplotlib.pyplot as plt
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
train_loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(train_acc, 'bo', color='r', label='train acc')
plt.plot(val_acc, 'b', color='b', label='validation acc')
plt.legend()
plt.show()
plt.plot(train_loss, 'bo', color='r', label='train loss')
plt.plot(val_loss, 'b', color='b', label='validation loss')
plt.legend()
plt.show()