[머신러닝] Outlier 2
이상치(Outlier) 처리-(2)(Z-Score)
이상치 처리하는데 많이 사용되는 두가지 방법 Tukey Outlier와 Z-Score 중 Z-Score에 대해서 알아본다.
Z-Score
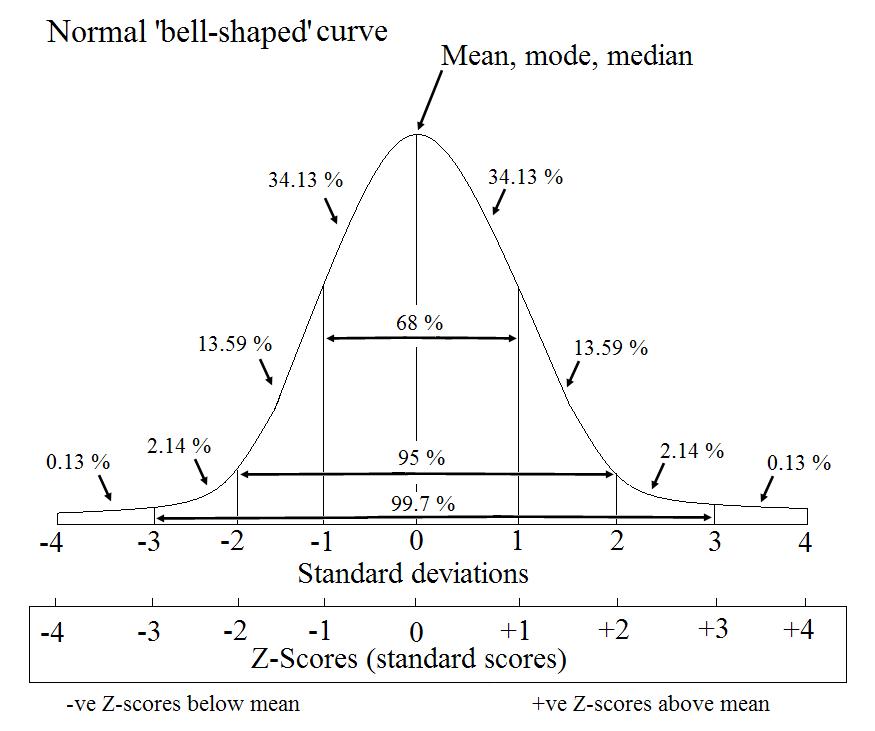
Z-Score는 표준 점수(Standard score)라고도 불리며 정규분포를 만들고 각 데이터가 표준편차상에 어떤 위치를 차지하는지를 보여주는 차원없는 수치이다. 미테 그림에서 표쥰점수가 대체로 1.8이상 -1.8 이하값에 속하는것들을 이상값으로 정의한다.
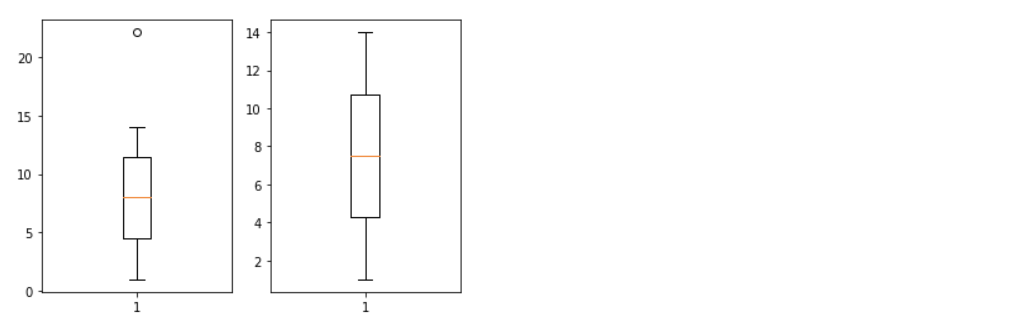
다음의 예제를 살펴보자.
import numpy as np
import matplotlib.pyplot as plt
data = np.array([1,2,3,4,5,6,7, 8,9, 10,11,12,13,14, 22.1])
print(data)
## [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 22.1]
fig = plt.figure()
fig.add_subplot(1,2,1)
plt.boxplot(data)

scipy
scipy 에서는 Z-Score를 이용해 이상치를 제거하는 library를 제공한다.
scipy에서stats를 import 하면 된다.stats는 statistics의 약자? 인듯 하다.
stats.zscore
from scipy import stats
## stats.zscore를 사용하면 각 data의 Z-Score값을 계산해준다.
print(stats.zscore(data))
## [-1.40160702 -1.21405925 -1.02651147 -0.8389637 -0.65141593 -0.46386816
## -0.27632038 -0.08877261 0.09877516 0.28632293 0.4738707 0.66141848
## 0.84896625 1.03651402 2.55565098]
- 이상치 처리
zscore_threshold = 1.8 # 보통 2 또는 1.8 을 많이 사용한다.
outliers = np.abs(stats.zscore(data))> zscore_threshold
data = data[~outliers]
print(data)
## [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.]
fig.add_subplot(1,2,2)
plt.boxplot(data)
plt.show()