스케줄러
Observable, Single, ConnectableObservable 클래스로 만들어준 데이터 흐름과,
map(), filter(), flatMap()함수 를 배웠음
이번 장에는 RxJAVA의 핵심요소로써 비동기 프로그래밍의 꽃! 스케줄러에 대해서 알아볼까나
@Override
public void marbleDiagram() {
String[] objs = {star(RED), triangle(YELLOW), pentagon(GREEN)};
Observable<String> source = Observable.fromArray(objs)
.doOnNext(data -> Log.v("Original data = " + data))
.subscribeOn(Schedulers.newThread())
.observeOn(Schedulers.newThread())
.map(Shape::flip);
source.subscribe(Log::i);
CommonUtils.sleep(500);
CommonUtils.exampleComplete();
}
RxNewThreadScheduler-1 | Original data = 1-S
RxNewThreadScheduler-1 | Original data = 2-T
RxNewThreadScheduler-1 | Original data = 3-P
RxNewThreadScheduler-2 | value = (flipped)1-S
RxNewThreadScheduler-2 | value = (flipped)2-T
RxNewThreadScheduler-2 | value = (flipped)3-P
subscribeOn 은 구독자가 Observable에 subscribe()함수를 호출하여 구독할 때 실행되는 스레드를 지정.
observeOn 은 Observable에 subscribe에서 생성한 데이터 흐름이 여기저기 함수를 거치며 처리될 때 동작이 어느 스레드에서 일어나는지 지정
new Thread를 만들었기 때문에 위에 뉴스레드-1에서 Original데이터 발행하고, observeOn에서도 new Thread했기 때문에 new Thread2 발행된 토큰들이 온다.
public void observeOnRemoved() {
String[] objs = {star(RED), triangle(YELLOW), pentagon(GREEN)};
Observable<String> source = Observable.fromArray(objs)
.doOnNext(data -> Log.v("Origianl data = " + data))
.subscribeOn(Schedulers.newThread())
//removed .observeOn(Schedulers.newThread())
.map(Shape::flip);
source.subscribe(Log::i);
CommonUtils.sleep(500);
}
만약 이렇게 되어 있다면? subscribeOn에 의해 하나의 스레드안에서 발행 결과를 담당할 것이고 결과는 다음과같다.
RxNewThreadScheduler-3 | Origianl data = 1-S
RxNewThreadScheduler-3 | value = (flipped)1-S
RxNewThreadScheduler-3 | Origianl data = 2-T
RxNewThreadScheduler-3 | value = (flipped)2-T
RxNewThreadScheduler-3 | Origianl data = 3-P
RxNewThreadScheduler-3 | value = (flipped)3-P
- 스케줄러는 RxJAVA코드는 어느 스레드에서 실행할지 지정할 수 있다.
- subscribeOn()함수와 observeOn() 함수를 모두 지정하면 Observable에서 데이터 흐름이 발생하는 스레드와 처리된 결과를 구독자에게 발생하는 스레드를 분리할 수 있다.
- subscribeOn() 함수만 호출하면 Observable의 모든 흐름이 동일한 스레드에서 실행된다.
- 스케줄러를 별도로 지정하지 않으면 현재(main) 스레드에서 동작을 실행한다.
스켸줄러의 종류에는 총 5가지 있다.
간략히
뉴 스레드 스케줄러 => newThread()
싱글 스레드 스케줄러 => single()
계산 스케줄러 => computation()
IO 스케줄러 => io()
트램펄린 스케줄러 => trampoline()
메인 스레드 스케줄러 지원 X
테스트 스케줄러 지원 X
뉴 스케줄러 스케줄러
새로운 스레드를 생성, 새로운 스레드를 만들어 어떤 동작을 실행하고 싶을 때 Scheduler.newThread()를 인자로 넣어주면 됨. 그럼 뉴 스레드 스케줄러는 요청을 받을 때마다 새로운 스레드를 생성합니다.
RxJAVA의 스케줄러는 subscribeOn()함수와 observeOn()함수에 나눠서 적용할 수 있는데 두 함수의 개념을 정확하게 알지 못한 상태면 더욱 혼란 스럽다.
다시한번 위 두개의 차이를 말해보면
subscribeOn()은 subscribe함수가 호출되어 구독 될때 실행되는 스레드.
observeOn()은 나온 결과를 어디 스레드에서 발행할 것인가를 담당.
public void basic() {
String[] orgs = {RED, GREEN, BLUE};
Observable.fromArray(orgs)
.doOnNext(data -> Log.v("Original data : " + data))
.map(data -> "<<" + data + ">>")
.subscribeOn(Schedulers.newThread())
.subscribe(Log::i);
CommonUtils.sleep(500);
Observable.fromArray(orgs)
.doOnNext(data -> Log.v("Original data : " + data))
.map(data -> "##" + data + "##")
.subscribeOn(Schedulers.newThread())
.subscribe(Log::i);
CommonUtils.sleep(500);
}
RxNewThreadScheduler-1 | Original data : 1
RxNewThreadScheduler-1 | value = <<1>>
RxNewThreadScheduler-1 | Original data : 3
RxNewThreadScheduler-1 | value = <<3>>
RxNewThreadScheduler-1 | Original data : 5
RxNewThreadScheduler-1 | value = <<5>>
RxNewThreadScheduler-2 | Original data : 1
RxNewThreadScheduler-2 | value = ##1##
RxNewThreadScheduler-2 | Original data : 3
RxNewThreadScheduler-2 | value = ##3##
RxNewThreadScheduler-2 | Original data : 5
RxNewThreadScheduler-2 | value = ##5##
subscribeOn만 있고 observeOn은 없다. subscribe()함수가 호출될 때 구독하는 스레드를 Scheduler.newThread()함으로써 받고 처리하는 모든 일련의 과정을 하나의 스레드에서 처리한다.
만약에 observeOn(Schedulers.newThread())를 넣는다면 분리되어 나올것으로 예측했고 실제로도 그렇게 나왔다.
RxNewThreadScheduler-1 | Original data : 1
RxNewThreadScheduler-1 | Original data : 3
RxNewThreadScheduler-1 | Original data : 5
RxNewThreadScheduler-2 | value = <<1>>
RxNewThreadScheduler-2 | value = <<3>>
RxNewThreadScheduler-2 | value = <<5>>
계산 스케줄러
interval() 함수 활용할 때 원형을 살펴보면
@CheckReturnValue
@SchedulerSupport(SchedulerSupport.COMPUTATION)
public static Observable<Long> interval(long period, TimeUnit unit) {
return interval(period, period, unit, Schedulers.computation());
}
computation 라는 스레드에서 동작하도록 되어있었는데, 해당 스레드가 계산 스레드이다.
@CheckReturnValue
@SchedulerSupport(SchedulerSupport.CUSTOM)
public static Observable<Long> interval(long period, TimeUnit unit, Scheduler scheduler) {
return interval(period, period, unit, scheduler);
}
CUSTOM의 경우 알아서 선택해서 할 수 있음.
계산 스케줄러는 CPU에 대응하는 계산용 스케줄러로, ‘계산’작업을 할 때는 대기 시간 없이 빠르게 결과를 도출하는 것이 중요하다. 내부적으로 스레드 풀을 생성하며 스레드 개수는 기본적으로 프로세서 개수와 동일합니다.
public void basic() {
String[] orgs = {RED, GREEN, BLUE};
Observable<String> source = Observable.fromArray(orgs)
.zipWith(Observable.interval(100L, TimeUnit.MILLISECONDS),
(a,b) -> a);
//Subscription #1
source.map(item -> "<<" + item + ">>")
.subscribeOn(Schedulers.computation())
.subscribe(Log::i);
//Subscription #2
source.map(item -> "##" + item + "##")
.subscribeOn(Schedulers.computation())
.subscribe(Log::i);
CommonUtils.sleep(1000);
CommonUtils.exampleComplete();
}
RxComputationThreadPool-3 | value = ##1##
RxComputationThreadPool-3 | value = <<1>>
RxComputationThreadPool-3 | value = ##3##
RxComputationThreadPool-3 | value = <<3>>
RxComputationThreadPool-3 | value = ##5##
RxComputationThreadPool-3 | value = <<5>>
RxComputationThreadPool-3 | value = <<1>>
RxComputationThreadPool-4 | value = ##1##
RxComputationThreadPool-3 | value = <<3>>
RxComputationThreadPool-4 | value = ##3##
RxComputationThreadPool-4 | value = ##5##
RxComputationThreadPool-3 | value = <<5>>
데이터의 흐름은 동일하게 흐르지만 결과는 매번 다르다. 위에 말한것 처럼 ‘계산’ 작업을 할 때는 대기 시간 없이 빠르게 결과를 도출하는 것이 중요하기 때문에!!
그리고 여기에서 zipWith()을 중요성 계속해서 강조하고 있다! 나도 활용하기위해 노력하자.
데이터와 시간을 합성해서 발행한다.
IO 스케줄러
계산 스케줄러와는 다르게 네트워크상의 요청을 처리하거나 각종 입,출력 작업을 실행하기 위한 스케줄러.
계산 스케줄러와 다른 점은 기본으로 생성되는 스레드 개수가 다르다는 것. 즉, 계산 스케줄러는 CPU개수 만큼 스레드를 생성하지만 IO스케줄러는 필요할 때마다 스레드를 계속 생성. 입,출력 작업은 비동기로 실행되지만 결과를 얻기까지 대기 시간이 길다.
두 스케줄러를 비교하면
계산 스케줄러러는 일반적인 계산 작업
IO 스케줄러는 네트워크상의 요청, 파일 입출력, DB쿼리 등
public void basic() {
//list up files on C drive root
String root = "c:\\";
File[] files = new File(root).listFiles();
Observable<String> source = Observable.fromArray(files)
.filter(f -> !f.isDirectory())
.map(f -> f.getAbsolutePath())
.subscribeOn(Schedulers.io());
source.subscribe(Log::i);
CommonUtils.sleep(500);
CommonUtils.exampleComplete();
}
나는 맥이라 c파일이 없어서 볼수 없지만 차이점을 약간 이해할 수 있을거 같다.
트램펄린 스케줄러
새로운 스레드를 생성하지 않고 현재 스레드에 무한한 크기의 대기 행렬(Queue)를 생성하는 스케줄러입니다. 새로운 스레드를 생성하지 않는다는 것과 대기 행렬을 자동으로 만들어 준다는 것이 뉴 스레드 스케줄러, 계산 스케줄러, IO스케줄러와 다른점.
public void run() {
String[] orgs = {"RED", "GREEN", "BLUE"};
Observable<String> source = Observable.fromArray(orgs);
//Subscription #1
source.subscribeOn(Schedulers.trampoline())
.map(data -> "<<" + data + ">>")
.subscribe(Log::i);
//Subscription #2
source.subscribeOn(Schedulers.trampoline())
.map(data -> "##" + data + "##")
.subscribe(Log::i);
CommonUtils.sleep(500);
CommonUtils.exampleComplete();
}
main | value = <<RED>>
main | value = <<GREEN>>
main | value = <<BLUE>>
main | value = ##RED##
main | value = ##GREEN##
main | value = ##BLUE##
두번째의 subscribeOn을 지워도 처음 발행된 스케줄러에서 동작되어 문제없이 동작한다.
싱글 스레드 스케줄러
RxJAVA내부에서 단일 스레드를 별도로 생성하여 구독작업을 처리합니다. 단, 생성된 스레드는 여러 번 구독 요청이 와도 공통으로 사용합니다.
public void basic() {
Observable<Integer> numbers = Observable.range(100, 5);
Observable<String> chars = Observable.range(0, 5)
.map(CommonUtils::numberToAlphabet);
*** numbers.subscribeOn(Schedulers.single()) ***
.subscribe(Log::i);
*** chars.subscribeOn(Schedulers.single()) ***
.subscribe(Log::i);
CommonUtils.sleep(500);
CommonUtils.exampleComplete();
}
RxSingleScheduler-1 | value = 100
RxSingleScheduler-1 | value = 101
RxSingleScheduler-1 | value = 102
RxSingleScheduler-1 | value = 103
RxSingleScheduler-1 | value = 104
RxSingleScheduler-1 | value = A
RxSingleScheduler-1 | value = B
RxSingleScheduler-1 | value = C
RxSingleScheduler-1 | value = D
RxSingleScheduler-1 | value = E
오직 하나의 스케쥴러에서만 동작되게끔 하는 스케줄러
Executor 변환 스케줄러
자바에서는 java.util.current 패키지에서 제공하는 실행자를 변환하여 스케줄러를 생성할 수 있습니다. 하지만 Executor클래스와 스케줄러의 동작방식과 다르므로 추천 방법은 아니다.
기존에 상용하던 Executor 클래스를 활용하여 스케줄러를 지정하는 방법은 다음과 같다.
public void run() {
final int THREAD_NUM = 10;
String[] data = {"RED", "GREEN", "BLUE"};
Observable<String> source = Observable.fromArray(data);
Executor executor = Executors.newFixedThreadPool(THREAD_NUM);
source.subscribeOn(Schedulers.from(executor))
.subscribe(Log::i);
source.subscribeOn(Schedulers.from(executor))
.subscribe(Log::i);
CommonUtils.sleep(500);
CommonUtils.exampleComplete();
}
pool-1-thread-2 | value = RED
pool-1-thread-2 | value = GREEN
pool-1-thread-2 | value = BLUE
pool-1-thread-1 | value = RED
pool-1-thread-1 | value = GREEN
pool-1-thread-1 | value = BLUE
잘 보면 동시성 제어를 활용하는 것에 큰 장점이 있는 RxJAVA이지만, Executor 스케줄러는 자바 내장 스레드를 활용할 수 있다는 것에 큰 강점을 두고 있는거 같다.
스케줄러를 활용하여 콜백 지옥 벗어나기
서버와 통신하는 네트워크 프로그래밍을 할 떄 마주치는 콜백 지옥을 RxJAVA는 어떻게 해결하는지 살펴봅시다.
private static final String FIRST_URL = "https://api.github.com/zen";
private static final String GITHUB_ROOT = "https://raw.githubusercontent.com/yudong80/reactivejava/master/";
private static final String SECOND_URL = GITHUB_ROOT + "/samples/callback_hell";
private final OkHttpClient client = new OkHttpClient();
private Callback onSuccess = new Callback() {
@Override
public void onFailure(Call call, IOException e) {
e.printStackTrace();
}
@Override
public void onResponse(Call call, Response response) throws IOException {
Log.i(response.body().string());
}
};
public void run() {
Request request = new Request.Builder()
.url(FIRST_URL)
.build();
client.newCall(request).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
e.printStackTrace();
}
@Override
public void onResponse(Call call, Response response) throws IOException {
Log.i(response.body().string());
//add callback again
Request requst = new Request.Builder()
.url(SECOND_URL)
.build();
client.newCall(request).enqueue(onSuccess);
}
});
}
public static void main(String[] args) {
CallbackBadExample demo = new CallbackBadExample();
demo.run();
}
이 코드를 이해했다면, 리퀘스트를 보내고 성공했다면, 가정하여 한번 더 보낸다. 이는 콜백지옥을 만들어 내어
가독성을 떨어뜨리고 개발자로 하여금 불안을 일으키는 요소가 된다.
위의 콜백코드를 RxJAVA를 활용해 깔끔하게 만들어보자.
public void usingConcat() {
CommonUtils.exampleStart();
Observable<String> source = Observable.just(FIRST_URL)
.subscribeOn(Schedulers.io())
.map(OkHttpHelper::get)
.concatWith(Observable.just(SECOND_URL)
.map(OkHttpHelper::get));
source.subscribe(Log::it);
CommonUtils.sleep(5000);
CommonUtils.exampleComplete();
}
concat를 활용해서 두개의 Observable를 결합한다. 마치.. 하나 뒤에 하나가 붙는 느낌?
이렇게 하면 선언적 동시성(Declarative Concurrency)하게 되어 순수한 비즈니스 로직과 비동기 동작을 위한 스레드 부분을 구별할 수 있도록 합니다. 또한 가독성도 좋아집니다.
또는
public void usingZip() {
CommonUtils.exampleStart();
Observable<String> first = Observable.just(FIRST_URL)
.subscribeOn(Schedulers.io())
.map(OkHttpHelper::get);
Observable<String> second = Observable.just(SECOND_URL)
.subscribeOn(Schedulers.io())
.map(OkHttpHelper::get);
Observable.zip(first, second,
(a, b) -> ("\n>>" + a + "\n>>" + b))
.subscribe(Log::it);
CommonUtils.sleep(5000);
}
zip을 활용해서 동시성 네트워크를 호출하는 Observable를 결합한다. 동시성 네트워크를 활용하게 되면 병렬 Observable 되어 시간이 줄어든다.
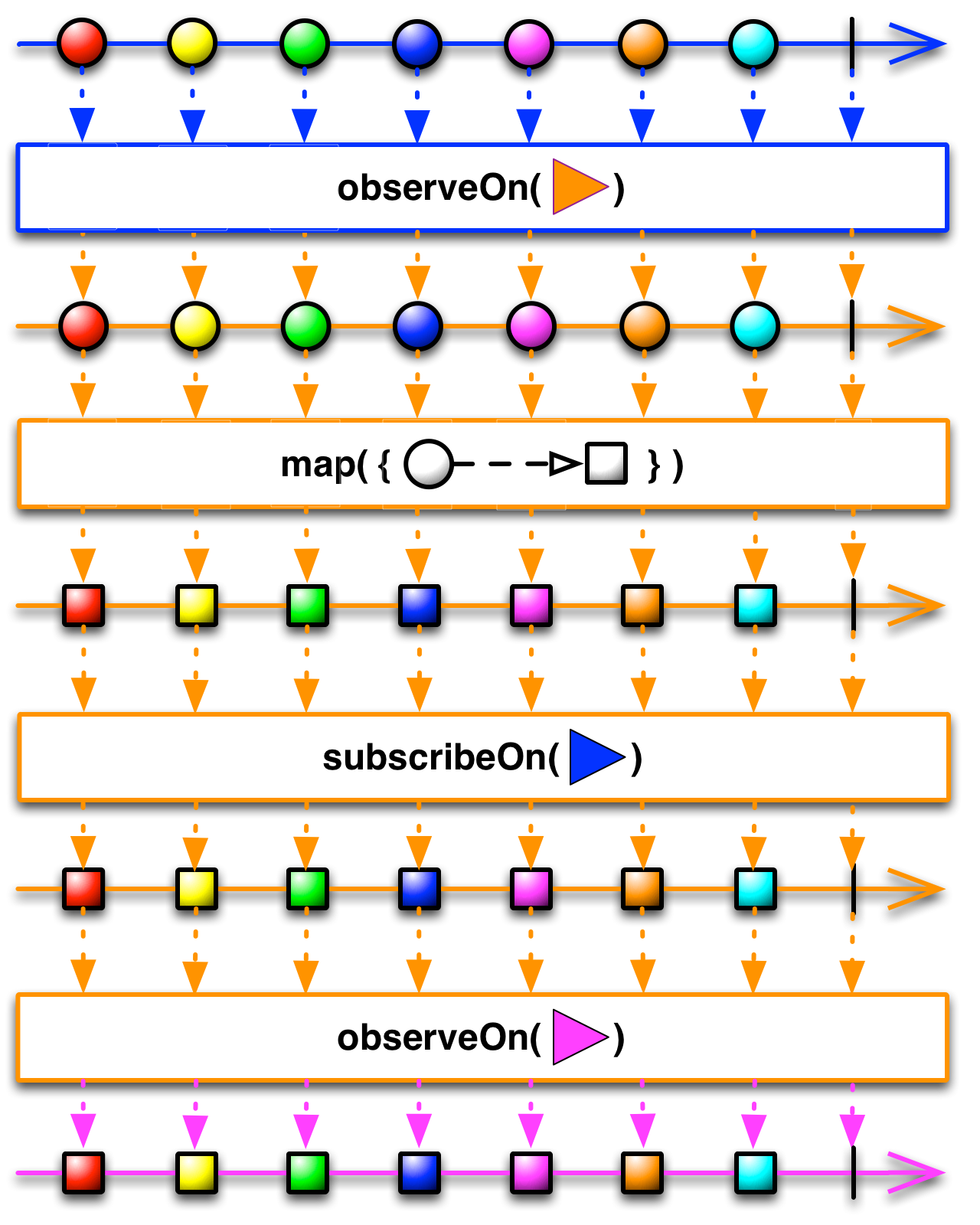
observeOn() 함수의 활용
이전에 observeOn 와 subscribeOn의 차이를 설명했다.
다시 해보면 subscribeOn은 subscribe를 호출할 때 데이터 흐름을 발행하는 스레드를 지정.
observeOn은 처리된 결과를 구독자에게 전달하는 스레드를 지정합니다.
여기서 차이점은 subscribeOn함수는 처음 지정한 스레드를 고정시키므로 다시 subscribeOn()함수를 호출해도 무시합니다. 하지만 observeOn() 함수는 다릅니다. 스레드가 변화 됩니다.
실습 OpenWheatherMap 연동 책을 참조.
public class OpenWeatherMapV1 {
private static final String URL = "http://api.openweathermap.org/data/2.5/weather?q=London&APPID=";
public void run() {
Observable<String> source = Observable.just(URL + API_KEY)
.map(OkHttpHelper::getWithLog)
.subscribeOn(Schedulers.io());
//어떻게 호출을 한번만 하게 할 수 있을까?
Observable<String> temperature = source.map(this::parseTemperature);
Observable<String> city = source.map(this::parseCityName);
Observable<String> country = source.map(this::parseCountry);
CommonUtils.exampleStart();
Observable.concat(temperature,
city,
country)
.observeOn(Schedulers.newThread())
.subscribe(Log::it);
CommonUtils.sleep(1000);
}
private String parseTemperature(String json) {
return parse(json, "\"temp\":[0-9]*.[0-9]*");
}
private String parseCityName(String json) {
return parse(json, "\"name\":\"[a-zA-Z]*\"");
}
private String parseCountry(String json) {
return parse(json, "\"country\":\"[a-zA-Z]*\"");
}
private String parse(String json, String regex) {
Pattern pattern = Pattern.compile(regex);
Matcher match = pattern.matcher(json);
if (match.find()) {
return match.group();
}
return "N/A";
}
public void run() {
CommonUtils.exampleStart();
//어떻게 호출을 한번만 하게 할 수 있을까? 이부분을
Observable<String> source = Observable.just(URL + API_KEY)
.map(OkHttpHelper::getWithLog)
.subscribeOn(Schedulers.io());
Observable<String> temperature = source.map(this::parseTemperature);
Observable<String> city = source.map(this::parseCityName);
Observable<String> country = source.map(this::parseCountry);
// 이렇게 수정 가능함.
Observable<String> source = Observable.just(URL + API_KEY)
.map(OkHttpHelper::getWithLog)
.subscribeOn(Schedulers.io())
.share()
.observeOn(Schedulers.newThread());
source.map(this::parseTemperature).subscribe(Log::it);
source.map(this::parseCityName).subscribe(Log::it);
source.map(this::parseCountry).subscribe(Log::it);
CommonUtils.sleep(1000);
}
private String parseTemperature(String json) {
return parse(json, "\"temp\":[0-9]*.[0-9]*");
}
private String parseCityName(String json) {
return parse(json, "\"name\":\"[a-zA-Z]*\"");
}
private String parseCountry(String json) {
return parse(json, "\"country\":\"[a-zA-Z]*\"");
}
private String parse(String json, String regex) {
Pattern pattern = Pattern.compile(regex);
Matcher match = pattern.matcher(json);
if (match.find()) {
return match.group();
}
return "N/A";
}
여기서 share() 함수를 보면
@CheckReturnValue
@SchedulerSupport(SchedulerSupport.NONE)
public final Observable<T> share() {
return publish().refCount();
}
publish() 를 살펴보면
/**
* Returns a {@link ConnectableObservable}, which is a variety of ObservableSource that waits until its
* {@link ConnectableObservable#connect connect} method is called before it begins emitting items to those
* {@link Observer}s that have subscribed to it.
* <p>
* <img width="640" height="510" src="https://raw.github.com/wiki/ReactiveX/RxJava/images/rx-operators/publishConnect.png" alt="">
* <dl>
* <dt><b>Scheduler:</b></dt>
* <dd>{@code publish} does not operate by default on a particular {@link Scheduler}.</dd>
* </dl>
*
* @return a {@link ConnectableObservable} that upon connection causes the source ObservableSource to emit items
* to its {@link Observer}s
* @see <a href="http://reactivex.io/documentation/operators/publish.html">ReactiveX operators documentation: Publish</a>
*/
@CheckReturnValue
@SchedulerSupport(SchedulerSupport.NONE)
public final ConnectableObservable<T> publish() {
return ObservablePublish.create(this);
}
ConnectableObservable 클래스 사용. 차가운 Observable을 뜨거운 Observable 로 변환