# Kubernetes, k8s
1. 개요
- 쿠버네티스는 도커 등을 기반으로 컨테이너화된 애플리케이션을 배포, 확장, 관리하는 것을 자동화할 수 있게 해주는 오케스트레이션 플랫폼
- 구글에 의해 설계되었고, 현재 리눅스 재단 CNCF에 의해 관리
- 여러 클러스터의 호스트 간에 애플리케이션 컨테이너의 배치, 스케일링, 운영을 자동화하기 위한 플랫폼 제공
- 도커를 포함한 일련의 컨테이너 도구들과 함께 동작
- Go 언어로 구현되었으며, 벤더나 플랫폼에 종속되지 않기 때문에 퍼블릭 클라우드, 프라이빗 클라우드, 베이베탈에도 배포 가능
2. 개념
2-1. 마스터와 노드
- 쿠버네티스는 클러스터 구조로, 클러스터 전체를 관리하는 컨트롤로써 마스터(마스터 노드)가 존재하고, 컨테이너가 배포되는 머신인 노드(워커 노드)가 존재

2-2. 오브젝트(object)
- 오브젝트 : 가장 기본적인 구성 단위가 되는 기본 오브젝트(Basic Object)와 이 기본 오브젝트를 생성하고 관리하는 추가적인 기능을 가진 컨트롤러(Controller) 로 이루어짐
- 오브젝트의 스펙(설정) 이외에 추가 정보인 메타 정보들로 구성
- 오브젝트 스펙(Object Spec) : 오브젝트들은 모두 오브젝트의 특성(설정정보)을 기술한 오브젝트 스펙으로 정의 / CLI를 통해 오브젝트 생성 시 인자로 전달하거나 YAML이나 JSON 파일로 정의
- 기본 오브젝트(Basic Object) : 쿠버네티스에 의해서 배포 및 관리되는 가장 기본적인 오브젝트는 컨테이너화되어 배포되는 애플리케이션의 워크로드를 기술하는 오브젝트로, Pod, Service, Volume, Namespace
2-2-1. Pod
- 쿠버네티스에서 가장 기본적인 배포 단위로, 컨테이너를 포함하는 단위
- 쿠버네티스는 컨테이너를 개별적으로 하나씩 배포하는 것이 아닌, Pod 단위로 배포
- Pod는 하나 이상의 컨테이너 포함
Object Spec
apiVersion : v1
kind : Pod
metadata:
name: nginx
spec:
containers:
-name: nginx
image: nginx:1.7.9
ports:
-containerPort: 8090
- apiVersion : 이 스크립트를 실행하기 위한 쿠버네티스 API 버전
- kind : 리소스의 종류 정의
- metadata : 리소스의 각종 메타 데이터
- spec : 리소스에 대한 상세 스펙 정의
특징
- Pod 내의 컨테이너는 IP와 Port를 공유
- Pob 내에 배포된 컨테이너 간에는 디스크 볼륨 공유

2-2-2. Volume
- Pod가 기동할 때, 디폴트로 컨테이너마다 로컬 디스크를 생성 but, 영구적이지 않음
- volume은 컨테이너의 외장 디스크
- Pod가 기동할 때, 컨테이너에 마운트해서 사용
- 다양한 외장 디스크를 추상화된 형태로 제공 (ex: iSCSI, NFS, AWS EBS, Google PD, github, glusterfs 등)
2-2-3. Service
- 여러 개의 Pod를 로드밸런서를 이용해서 하나의 IP와 포트로 묶어 서비스 제공
- Pod의 경우, 동적으로 생성이 되고 장애가 생기면 자동으로 리스타트 되면서 IP가 바뀌기 때문에 로드밸런서에서 Pod의 목록을 지정할 때 IP 목록을 사용하기 어려움 / 오토 스케일링으로 인하여 Pod가 동적으로 추가 또는 삭제되기 때문에, 로드밸런서가 유연하게 선택해줘야 하고 이를 위해 사용하는 것이 라벨(label)과 라벨 셀렉터(label selector)
- 서비스를 정의할 때, 어떤 Pod를 서비스로 묶을 것인지를 정의하는 것이 라벨 셀렉터
- 각 Pod를 생성할 때, 메타 데이터 정보 부분에 라벨 정의 가능
- 서비스는 라벨 셀렉터에서 특정 라벨을 가지고 있는 Pod만 선택하여 서비스를 묶음

2-2-4. Namespace
- 하나의 쿠버네티스 클러스터 내의 논리적인 분리 단위
- Pod, Service 등은 네임스페이스 별로 생성이나 관리 가능
- 사용자 권한도 네임스페이스 별로 부여 가능
- 하나의 클러스터 내에 개발/운영/테스트 환경이 있다면, 클러스터를 개발/운영/테스트 3개의 네임스페이스로 나눠서 운영 가능
- 네임스페이스 별로 리소스 할당량 지정 가능
- 논리적인 분리 단위이므로, 다른 네임스페이스 간의 Pod라도 통신 가능

2-2-5. Label
- 쿠버네티스의 리소스를 선택하는데 사용
- 각 리소스는 라벨을 가질 수 있으며, 라벨 검색 조건에 따라 특정 라벨을 가지고 있는 리소스만 선택 가능
- metadata 섹션에 키/값 쌍으로 정의 가능
- 하나의 리소스에는 여러 라벨을 동시에 적용 가능
2-3. 컨트롤러
- 기본 오브젝트들을 생성하고 관리하는 역할
- Replication Controller, Replication Set, DaemonSet, Job, StatefulSet, Deployment
2-3-1. Replication Controller
- Pod를 관리해주는 역할을 하며, 지정된 숫자로 Pod를 기동시키고 관리
- Equality 기반의 Selector 이용
- 3가지 파트 Replica의 수, Pod Selector, Pod Template로 구성
- Selector : Pod Selector는 라벨을 기반으로 RC가 관리한 Pod를 가지고 오는데 사용
- Replica 수 : RC에 의해서 관리되는 Pod의 수로, 그 숫자만큼 Pod의 수를 유지
- Pod Template : Pod를 추가로 기동할 때, Pod 정보(도커 이미지, 포트, 라벨 등) 정의

2-3-2. ReplicaSet
- Replication Controller의 새버전
- Set 기반의 Selector 이용
2-3-3. Deployment
- Replication controller와 Replica Set의 상위 추상화 개념
- 아래의 배포 과정을 자동화하고 추상화한 것이 Deployment
- Pod 배포를 위해서 RC를 생성하고 관리하는 역할
- 롤백을 위한 기존 버전의 RC 관리 등 여러가지 기능 포함

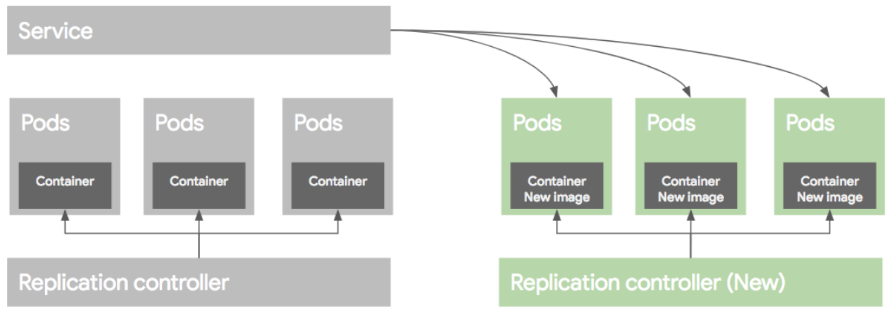
쿠버네티스 배포
-
블루/그린 배포
-
블루(예전) 버전으로 서비스 하고 있던 시스템을 그린(새로운)버전으로 배포한 후, 트래픽을 블루에서 그린으로 한번에 돌리는 방식
-
새로운 RC를 생성하고 새로운 템플릿으로 Pod를 생성한 후, Pod 생성이 끝나면 서비스를 새로운 Pod로 옮기는 방식
-
배포 완료 후, 문제가 없으면 예전 버전의 RC와 Pod를 지움
-
-
롤링 업그레이드
-
Pod를 하나씩 업그레이드 해가는 방식
-
새로운 RC를 생성한 후, 기존 RC에서 Replica 수를 하나 줄이고 새로운 RC에서 Replicat 수를 늘림


-
모든 작업을 마치면, 예전 버전의 Pod가 모두 빠지고 새 버전의 Pod만 서비스
-
배포가 잘못되었다면, 기존 RC의 replica 수를 원래대로 늘리고 새 버전의 replica 수를 0으로 설정하여 롤백 가능
-
2-3-4. DaemonSet
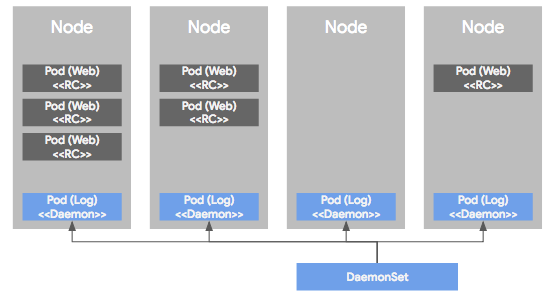
- DS는 Pod가 각각의 노드에서 하나씩만 돌게 하는 형태로 Pod를 관리하는 컨트롤러
- RC나 RS에 의해서 관리되는 Pod는 여러 노드의 상황에 따라 비균등적으로 배포, DS에 의해 관리되는 Pod는 모든 노드에 균등하게 하나씩만 배포
- 서버의 모니터링이나 로그 수집 용도로 이용
- 특정 노드에만 Pod를 배포할 수 있도록 node selector를 이용해서 라벨을 이용하여 특정 노드만 선택 가능
2-3-5. Job
- 배치나 한 번 실행되고 끝나는 형태의 워크로드 모델을 지원하는 컨트롤러
- Job에 의해서 관리되는 Pod는 Job이 종료되면 Pod를 같이 종료
- Job을 정의할 때, 컨테이너 스펙 부분에 Job을 수행하기 위한 커맨드를 같이 입력
2-3-6. StatefulSet
- 데이터베이스 등과 같이 상태를 가지고 있는 Pod를 지원하기 위한 컨트롤러
3. 아키텍처

3-1. 마스터와 노드
- 쿠버네티스는 마스터와 노드 두 개의 컴포넌트로 분리
- 마스터는 쿠버네티스의 설정 환경을 저장하고 전체 클러스터를 관리하는 역할
- 노드는 Pod나 컨테이너처럼 쿠버네티스 위에서 동작하는 워크로드를 호스팅하는 역할
3-1-1. 마스터
- 쿠버네티스 클러스터 전체를 컨트롤하는 시스템
- API 서버, 스케줄러, 컨트롤러 매니저, etcd로 구성
API server
- 쿠버네티스의 모든 기능들을 RESTful API로 제공하고 그에 대한 명령 처리
Etcd
- 쿠버네티스 클러스터의 데이터베이스 역할이 되는 서버로 설정값이나 클러스터의 상태를 저장하는 서버
- etcd라는 분산형 키/밸류 스토어 오픈소스로 쿠버네티스 클러스터의 상태나 설정 정보를 저장
Scheduler
- Pod, 서비스 등 각 리소스들을 적절한 노드에 할당하는 역할
Controller Manager
- 컨트롤러를 생성하고 이를 각 노드에 배포하며 관리하는 역할
DNS
- 쿠버네티스는 리소스의 엔드포인트를 DNS로 맵핑하고 관리
- 새로운 리소스가 생기면, 리소스에 대한 IP와 DNS 이름을 등록하여 DNS 이름을 기반으로 리소스에 접근
3-1-2. 노드
- 마스터 명령을 받고 실제 워크로드를 생성하여 서비스 하는 컴포넌트
- Kubelet, Kube-proxy, cAdvisor, Container runtime 로 구성
Kubelet
- 노드에 배포되는 에이전트
- 마스터의 API 서버와 통신하며, 노드가 수행해야 할 명령을 받아서 수행
- 노드의 상태 등을 마스터로 전달
Kube-proxy
- 노드로 들어오는 네트워크 트래픽을 적절한 컨테이너로 라우팅
- 로드밸런싱 등 노드로 들어오고 나가는 네트워크 트래픽을 프록시하고 노드와 마스터 간의 네트워크 통신을 관리
Container Runtime
- Pod를 통해서 배포된 컨테이너를 실행
- 종류에는 도커 컨테이너, rkt, Hyper container 등
cAdvisor
- 각 노드에서 기동되는 모니터링 에이전트
- 노드 내에서 가동되는 컨테이너들의 상태와 성능 등의 정보를 수집하여 마스터 서버의 API 서버로 전달
4. Volume
- Pod에 종속되는 디스크로, Pod 단위이기 때문에 여러 개의 컨테이너가 공유해서 사용 가능
4-1. 볼륨 종류
- 볼륨 타입
| Temp | Local | Network |
|---|---|---|
| emptyDir | hostPath | GlusterFS gitRepo NFS, iSCSI, gcePersistentDisk, AWS EBS, Fiber Channel, vSphereVolume, Secret, AzureDisk |
4-1-1. emptyDir
- Pod가 생성될 때 생성되고, 삭제될 때 같이 삭제되는 임시 볼륨
- 물리적으로 노드에서 할당해주는 디스크에 저장
4-1-2. hostPath
- 노드의 로컬 디스크의 경로를 Pod에 마운트해서 사용
- 같은 hostPath에 있는 볼륨은 여러 Pod 사이에서 공유되어 사용
4-1-3. gitRepo
- 생성 시에 지정된 git repogitory 의 특정 리비전의 내용을 Clone을 이용해서 받은 후에 디스크 볼륨을 생성하는 방식
- 물리적으로 emptyDir 이 생성되고, git repogitory 내용을 Clone으로 다운
4-2. PersistentVolume and PersistentVolumeClaim
- 인프라에 종속적인 부분은 시스템 관리자가 설정하도록 하고, 개발자는 간단하게 사용할 수 있도록 디스크 볼륨 부분에 PersistentVolume(PV) 와 PersistentVolumeClaim(PVC) 개념 도입
- 시스템 관리자가 실제 물리 디스크를 생성한 후, 이 디스크를 PV 라는 이름으로 쿠버네티스에 등록
- 개발자는 Pod를 생성할 때, 볼륨을 정의하고 볼륨 정의 부분에 물리적 디스크에 대한 특성이 아닌 PVC를 지정하여 PV와 연결
- 시스템 관리자가 생성한 물리 디스크를 쿠버네티스 클러스터에 표현한 것이 PV
- Pod의 볼륨과 PV를 연결하는 관계가 PVC

4-2-1. PersistentVolume
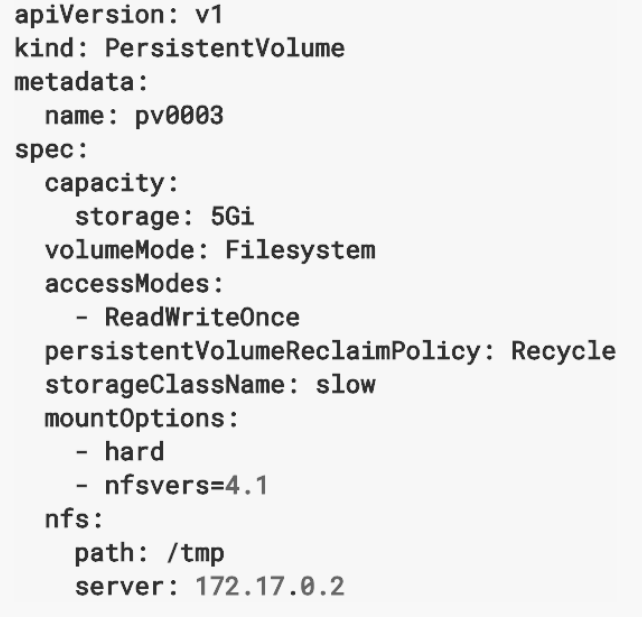
- Capacity : 볼륨의 용량 정의
- VolumeMode : 볼륨이 일반 Filesystem 인지 raw 볼륨인지 정의 / Filesystem 또는 raw 설정 가능
- Reclaim Policy : PV는 연결된 PVC가 삭제된 후, 다른 PVC에서 재사용이 가능하고 재사용시에 디스크의 내용을 지울지 유지할지에 대한 정책을 Reclaim Policy를 이용하여 설정 가능
- Retain : PV 내용 유지
- Recycle : 재사용이 가능 / 재사용시에는 자동으로 rm -rf로 삭제한 후 재사용
- Delete : 볼륨의 사용이 끝나면 해당 볼륨 삭제
- AccessMode : PV에 대한 동시 Pod에서 접근할 수 있는 정책 정의
- ReadWriteOnce(RWO) : 해당 PV는 하나의 Pod에만 마운트되고 읽고 쓰기가 가능
- ReadOnlyMany(ROX) : 여러 개의 Pod에 마운트, 동시 읽기가 가능하며 쓰기는 불가능
- ReadWriteMany(RWX) : 여러 개의 Pod에 마운트, 읽기, 쓰기 가능
PV 라이프사이클
- PV는 생성이 되면 Available 상태
- PVC에 바인딩이 되면 Bound 상태로 바뀌고 사용이 됨
- 바인딩된 PVC가 삭제되면 Released 상태
PV 생성
YAML 파일 등을 이용하여 수동으로 생성 및 필요시에 자동으로 생성 가능(Dynamic Provisioning)
4-2-2. PersistentVolumeClaim
PVC는 Pod의 볼륨과 PVC를 연결하는 관계 선언

- accessMode, VolumeMode는 PV와 동일
- resources는 PV와 같이 필요한 볼륨의 사이즈를 정의
- selector를 통해서 볼륨 선택 가능하며, label selector 방식으로 이미 생성되어 있는 PV 중에 label이 매칭되는 볼륨을 찾아서 연결
4-2-3. Dynamic Provisioning

- 시스템 관리자가 별도로 디스크를 생성하고 PV를 생성할 필요 없이 PVC만 정의하면 이에 맞는 물리 디스크 및 PV 생성을 자동화해주는 기능
5. Service
- Pod의 경우, IP가 랜던하게 지정되고 재시작될 때마다 변하기 때문에 고정된 엔드포인트로 호출이 어려움 / 여러 Pod에 같은 애플리케이션을 운용할 경우 로드밸런싱이 필요
- 서비스는 지정된 IP로 생성이 가능하고 여러 Pod를 묶어서 로드밸런싱이 가능하며 고유한 DNS를 가짐
- 멀티 포트 지원
- 로드 밸런싱 알고리즘
5-1. Service Type
- Cluster IP
- Load Balancer
- Node IP
- External name
5-1-1. Cluster IP
- 디폴트 설정으로 서비스에 클러스터 IP(내부 IP)를 할당
- 쿠버네티스 클러스터 내에서는 서비스에 접근기 가능하지만, 외부에서는 외부 IP를 할당 받지 못했기 때문에 접근이 불가능
5-1-2. Load Balancer
- 외부 IP를 가지고 있는 로드밸런서를 할당
- 외부에서 접근이 가능
5-1-3. Node Port
- 클러스터 IP만이 아닌 모든 노드의 IP와 포트를 통해서도 접근 가능
5-1-4. External Name
- 외부 서비스를 쿠버네티스 내부에서 호출하고자할 때 사용
- 쿠버네티스 클러스터 내의 Pod 들은 클러스터 IP를 가지고 있기 때문에 클러스터 IP 대역 밖의 서비스를 호출하고자 하면, 복잡한 설정이 필요
5-2. Headless Service
- 마이크로 서비스 아키텍처에서는 기능 콤포넌트에 대한 엔드포인트를 찾는 기능을 Service Discovery라고 하고, 서비스의 위치를 등록해놓는 서비스 디스커버리 솔루션을 제공(ex: etcd, consul 등)
- 이 경우, 쿠버네티스 서비스를 통해서 마이크로 서비스 컴포넌트를 관리하는 것이 아닌, 서비스 디스커버리 솔루션을 사용하기 때문에 서비스에 대한 IP 주소가 필요 없음
- 해당 기능들을 제공하기 위한 것이 Headless Service
- Cluster IP 등의 주소를 가지지 않고 DNS 이름을 가지며, DNS lookup 시 서비스의 IP가 아닌 해당 서비스에 연결된 Pod들의 IP 주소들을 리턴
5-3. Service Discovery
DNS
- 서비스 생성 시, [서비스명].[네임스페이스명].svc.cluster.local 이라는 DNS 명으로 쿠버네티스 내부 DNS에 등록
- 클러스터 내부에서는 이 DNS 명으로 서비스에 접근 가능
- DNS에서 리턴해주는 IP는 Cluster IP(내부 IP)
External IP
- 외부 IP를 명시적으로 지정
6. Ingress
1-1. 구성
기본 구성
HA 가능 마스터노드와 실제 앱이 구동하는 컨테이너들의 Pod를 호스팅하는 1개 이상의 워커 노드로 클러스터 구성
[이미지1]
1-2. 데이터센터 OS
데이터센터 OS
- 데이터센터는 하나의 큰 컴퓨터
- 데이터센터가 하나의 큰 컴퓨터가 되기 위해 데이터 센터 내의 많은 CPU, 메모리, 저장장치, 네트워킹 등의 세부사항들을 추상화하는 운영체제
- 쿠버네티스는 데이터센터 운영체제가 되기 위한 것 중 하나

1-3. 특징
- Automatic Bin-Packing : 가용성을 희생하지 않는 범위 안에서 리소스를 충분히 활용해서 컨테이너를 배치
- Self-Healing : 컨테이너 실행 실패, Node가 죽거나 반응이 없는 경우, Health check에 실패한 경우에 해당 컨테이너 서비스를 자동 복구
- Horizontal Scaling : Pod의 CPU 사용이나 App이 제공하는 Metric을 기반으로 ReplicaSet의 컨테이너를 스케줄링하여 성능 제어
- Service discovery and load balancing : Application 수정 없는 Service Discovery 메커니즘을 위해 Container에 고유 IP, 단일 DNS 이름을 제공하여 로드밸런싱
- Automated rollouts and rollbacks : application, configuration의 변경 시, 서비스의 중단없이 점진적으로 Container를 변경(Rolling, Update)하고 문제 발생시 Rollback
- Secret and configuration management : 보안키, configuration을 이미지의 변경없이 업데이트할 수 있고, 노출(expose)하지 않고 관리 사용
- Storage orchestration : local storage를 비롯해서 public cloud, network storage 등을 원하는 구성으로 자동 mount
- Batch Execution : batch, CI 작업의 수행을 관리할 수 있으며, 실패 시 컨테이너를 교체하는 것도 가능
2. 아키텍처
2-1. 아키텍처 구성
- 마스터노드와 1개 이상의 워커 노드(Worker Node)로 이뤄진 가상/물리 머신의 Set를 통해 클러스터 구성
- 마스터 노드 HA : Kube-scheduler와 kube-controller-manager는 마스터의 HA 구성에서도 1개만 Active
- Nodes @ Dashboard : k8s 클러스터를 위한 웹 UI 상의 node
- Pods @ Dashboard : k8s 클러스터를 위한 웹 UI 상의 노드별 동작 기능
- Nodes @ ntopng : k8s 생성 플로우와 사용 프로토콜
- Flow @ ntopng : k8s 노드 간 활성 플로우 모니터
- 마스터 노드
- etcd : 클러스터의 상태 저장 / k8s API object 저장 / Persistent Data Volume을 위한 SSD 권장
- API server
- Controller manager server
- Scheduler
- 워커 노드
- Kubelet : agent 로서 API server에 연결하여 데이터/볼륨/이미지/컨테이너 상태를 처리하며 Health check도 제공
- Kube-proxy : 외부 접속을 위한 서비스 라우팅과 로드밸런싱을 처리하고 iptable을 사용
- Ingress Controller : L7 기반 로드밸런싱 지원
2-2. 컨트롤러 매니저
- Kubernetes controller manager (KCM)에서 Cloud controller manager (CCM)을 분리하여 별도의 프로세스로 구동하여 클라우드에 의존적이던 KCM 환경을 개선
- KCM
- Node Controller
- Volume Controller
- Route Controller
- Service Controller
- CCM
- Node Controller
- Route Controller
- Service Controller
2-3. kube scheduler(스케줄러)
- Kube scheduler : 새로 생성한 Pod가 구동 하는 노드를 선택하고 감시하는 마스터의 구성 요소이며, 스케줄링의 결정을 위해 자원 요구, 하드웨어/소프트웨어/정책 억제, 친화와 비친화의 명시, 데이터의 위치, 워크로드 간 간섭과 데드라인 요소 수집
- 스케줄링 : 컨테이너가 실행 할 노드를 결정하며, CPU/메모리/동작 중인 컨테이너 수를 기반으로 고려하여 배치
- 스케줄링 방법
- 예측 가능 : 노드의 자원이나 성격으로 지정하며, Pod의 포트, Pod의 자원, 노드 지정 매치, 호스트 이름, 서비스 친화, 라벨
- 가중치 우선 순위 지정 : 가중치에 최적인 노드를 사용
2-4. kube proxy (프록시)
- kube-proxy : Pod 간 Node 간 통신을 지원
2-5. API 서버
- API server(kube-apiserver) : 대시보드와 CLI 등은 모두 API 서버를 통해 k8s를 연결 하며, API를 이용하는 프로그램 개발이 가능
- 쿠버네티스 요소들의 허브로, HTTP, HTTPS 기반의 RESTful API 제공
2-6. etcd 서버
- etcd(Distributed key-value store) : Configuration, Namespace, Replication 등의 pod/service 등의 상태 저장과 DNS 데이터 저장에 사용
- 쿠버네티스 클러스터의 많은 서비스가 etcd에 의존하며, 직접 접속하거나 kube-apiserver를 통함
2-7. 컨테이너 런타임
- 구성 요소의 도커 컨테이너화(Dockerizing) : k8s 마스터와 워크 노드들은 컨테이너화 한 구성 요소들과 프로세스로 동작
2-8. kubelet (에이전트)
- kubelet : 각 노드에서 구동하는 에이전트로 마스터에서 Pod의 정보를 제공. 마스터/워커 노드 모두에서 실행하고 Health check 기능도 포함
2-9. POD
- k8s의 동작을 위한 단위이며, 하나 이상의 컨테이너들로 구성하여 동일 IP/port로 localhost나 프로세스간 통신을 함. 컨테이너들은 스토리지를 공유
- 배치의 가장 작은 컨테이너 묶음 단위로서, Pod 내부의 컨테이너들은 테넌트 구성이 가능한 network namespace와 data volume을 공유하며 클러스터링 구성
3. K8s 네트워킹
3-1. CNI
-
CNI(Container Network Interface) : 런타임과 플러그인 간의 상호작용을 정의
- 런타임과 독립 : 컨테이너 네트워킹을 위해서 런타임에 독립적인 플랫폼
- 지원 OS : CoreOS, OpenShift, Mesos, Cloud Foundry, K8s, Kurma, rkt
-
Plugin 구성
- IPAM : 할당된 IP를 유지하고 로컬 데이터베이스
- VETH Pair : 자원들 간 필요한 연결의 논리적 링크 형성
- 기존 네트워크 요소 필요
-
Plugin 종류
이름 제조사 내용 ACI
[향 후 추가]
시스크-구글 협력하여 CCP
엔터프라이즈 컨테이너 솔루션 찾기
자동화된 배포, 버전업 관리 필수
비교표
빅데이터 서비스