[java] 아파치 플링크의 분산 처리(Distributed processing in Apache Flink)
아파치 플링크는 대규모 데이터 처리를 위한 분산 처리 프레임워크입니다. 분산 처리는 다수의 컴퓨터 또는 서버를 사용하여 작업을 분산시키고 데이터를 병렬로 처리하는 것을 의미합니다. 이를 통해 대용량 데이터에 대한 빠른 처리가 가능해집니다.
플링크 아키텍처
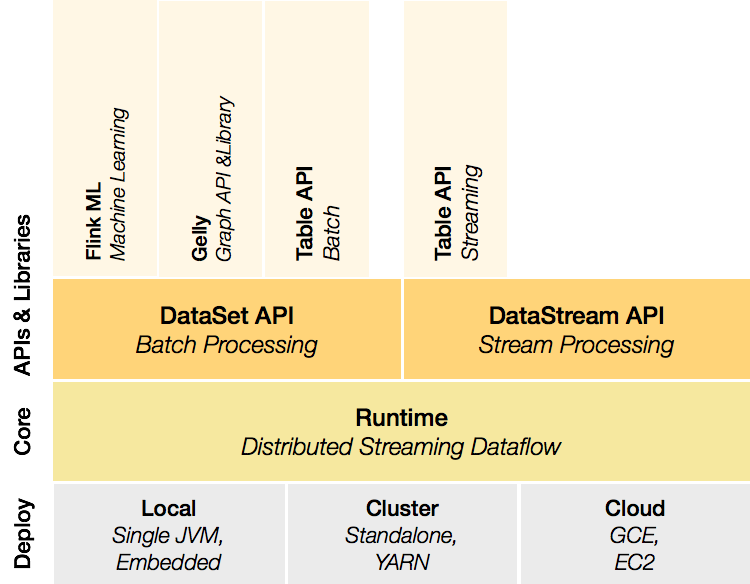
플링크 아키텍처는 크게 세 가지 주요 구성 요소로 구성됩니다.
- JobManager: 분산 처리 작업의 조율자이며, 작업의 스케줄링과 모니터링을 담당합니다.
- TaskManager: 실제 데이터 처리를 담당하는 워커 노드입니다. 여러 개의 TaskManager가 하나의 클러스터를 형성하여 데이터 처리 작업을 수행합니다.
- 분산 커뮤니케이션 스택: JobManager와 TaskManager 간의 통신과 데이터 교환을 위한 메시징 시스템입니다.
분산 처리의 장점
아파치 플링크의 분산 처리에는 여러 가지 장점이 있습니다.
- 높은 확장성: 플링크는 용량과 요구사항에 따라 클러스터의 크기를 조정할 수 있으며, 수많은 작업을 동시에 처리할 수 있습니다.
- 빠른 처리 속도: 플링크는 대용량의 데이터를 병렬로 처리하므로, 일괄 처리와 실시간 처리의 빠른 속도를 제공합니다.
- 고 가용성: 여러 개의 TaskManager를 사용하여 작업을 처리하므로, 일부 노드가 고장나더라도 작업을 계속할 수 있습니다.
- 유연한 데이터 처리: 플링크는 다양한 데이터 처리 방식을 지원하며, 배치 처리와 스트리밍 처리를 모두 지원합니다.
예제 코드
다음은 아파치 플링크에서 분산 처리를 수행하는 예제 코드입니다.
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class DistributedProcessingExample {
public static void main(String[] args) throws Exception {
// 플링크 실행 환경 생성
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 데이터 소스 생성
DataStream<String> inputStream = env.fromElements("Hello", "World", "Apache", "Flink");
// 데이터를 변환하는 맵 함수 적용
DataStream<Tuple2<String, Integer>> mappedStream = inputStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) {
return new Tuple2<>(value, value.length());
}
});
// 결과 출력
mappedStream.print();
// 실행
env.execute("Distributed Processing Example");
}
}
위 코드는 간단한 문자열을 입력으로 받아 각 문자열과 그 길이를 매핑하는 예제입니다. map 함수를 사용하여 입력 스트림의 각 요소에 대해 매핑 작업을 수행하고, 결과를 출력합니다.
결론
아파치 플링크는 대규모 데이터 처리 작업을 위한 강력한 분산 처리 프레임워크입니다. 이를 통해 빠르고 확장 가능한 데이터 처리를 구현할 수 있으며, 다양한 데이터 처리 방식을 지원합니다. 아파치 플링크를 사용하여 복잡한 데이터 처리 작업을 간단하게 구현해보세요.